Get more from LabVIEW and LabVIEW+
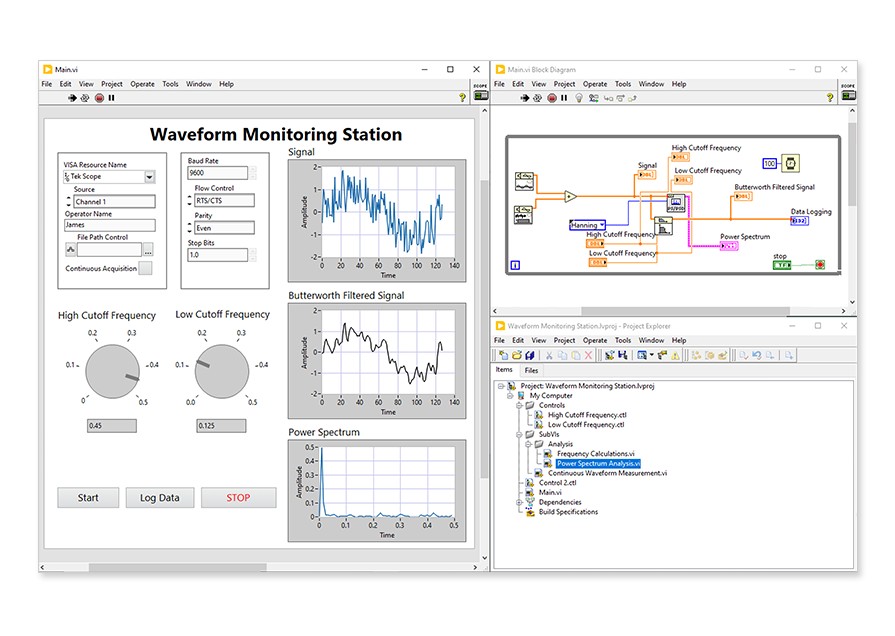
LabVIEW helps you work more quickly. Spend less time developing tests, automating instruments, analyzing data, and generating reports.
Featured Download
New FlexLogger Lite—Data in Minutes, Zero Coding
The new FlexLogger Lite edition is free companion software for NI data acquisition hardware. Quickly configure, log, and monitor mixed-signal systems with FlexLogger Lite—and upgrade anytime to the full-featured FlexLogger for more complex tasks such as automations, triggers, and alarms.
Build What's Next

NI offers the hardware, software, and services that help you turn real-world data into insights that drive your business decisions. Choose from products for desktop design and prototyping to fully automated production test systems.
Elevate Performance with Test
Unlocking the full benefits of test isn’t just about using a better tool. It requires an intentional strategy with automation, standardization, and digital transformation initiatives.